“You can’t handle the truth!”
Transfer learning to detect memorable movie quotes

In my opinion natural language processing (NLP) is one of the most exciting branches of machine learning. Over the past year there have been major breakthroughs in NLP, in which problems that were previously very difficult (or even impossible) to solve can now be solved better and with greater ease. One of the largest breakthroughs in NLP, has been the use of transfer learning. If you have read my previous blog post, you know that I am a big fan of transfer learning. Briefly, transfer learning is training a model to do one thing (typically on a large dataset like ImageNet) and use the weights from that model to solve another type of problem. For example, in my previous blog post I used a model that was pretrained on ImageNet to classify a small dataset of blue damsels and clownfish images into their appropriate fish species. Transfer learning is extremely useful because it allows for the use of small datasets to solve complex problems. Although this method is extremely popular in computer vision, it is largely not used within the NLP community. Recently, a paper demonstrated that transfer learning may be used to solve NLP problems; the authors termed this method as Universal Language Model Fine-tuning for Text Classification (ULMFiT). I believe the use of transfer learning is going to revolutionize the field and it already has in some ways.
Here, I am going to demonstrate the utility of transfer learning in NLP by using the ULMFiT method. My PhD is focused on memory (specifically from a computational cognitive neuroscience perspective), so appropriately enough, I decided to create a classifier that can detect whether a movie quote will be memorable or not. The code corresponding to this post is publicly available on my GitHub.
The Dataset
For the dataset, I used the Cornell Movie-Quotes Corpus. The dataset consists of memorable movie quotes, taken from IMDb’s memorable quotes. This consists of memorable quotes from about 1,000 movies and matching non-memorable quotes. The matching non-memorable quotes are from the same speaker, are similar in length, and were as close as possible in the script to the corresponding memorable quote. For example, from one of my favorite movies Fight Club:
Memorable: “Every evening I died and every evening I was born again. Resurrected”
Non-memorable: “I guess… when people think you’re dying, they really listen, instead…”
In the datatset there are 2,197 matching memorable-non-memorable quotes.
Modeling Approach: Language Model
As mentioned above, I am using a transfer learning approach. I am using a language model that was pretrained on a subset of Wikipedia. The architecture and pretrained weights of the model are available here. The model consists of three layers of AWD-LSTM, which is essentially an LSTM with dropout at various points. The pretrained model is a language model, meaning it is trained to predict the next word in a sentence. Even though we already have a pretrained language model, this model was trained on Wikipedia, which may be different from the movie quotes corpus of text. So, first, I fine-tuned the pretrained model on the movies quote dataset. I actually found that this step did not help improve the classifier accuracy on whether a quote was memorable or not. This is likely because the vocabulary size of the movie quotes dataset is very small (1,545 words).
Just a couple small notes about model training. First, as recommended in the ULMFiT paper, I used slanted triangular learning rates. As can be seen in the figure below, during model training, the learning rate rapidly increases and then gradually decreases during the rest of training.
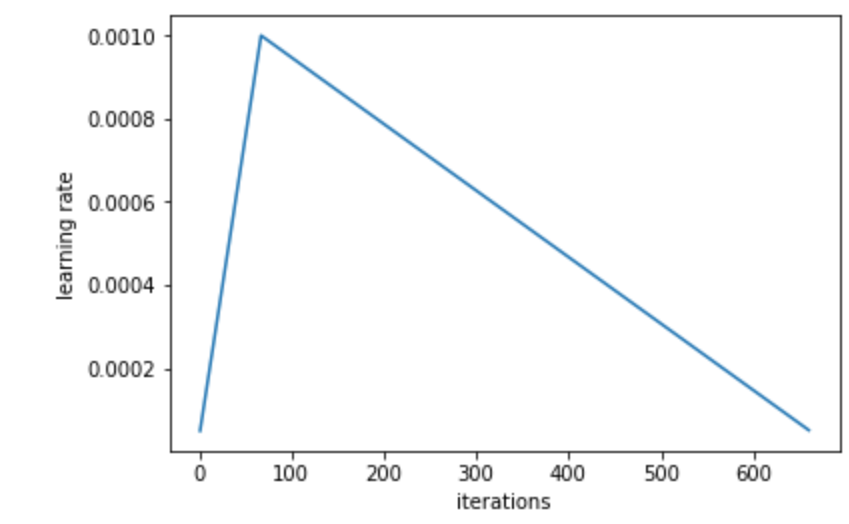
Second, I used gradual unfreezing. At the start of training, I just trained the embedding layers and then gradually started unfreezing/training the other layers. I also used discriminative fine-tuning, in which I used different learning rates for different layers. There are some layers, such as the output layer, that likely require more training than others, so we should use different learning rates for these layers.
I trained the model until I reached about 43% validation set accuracy.
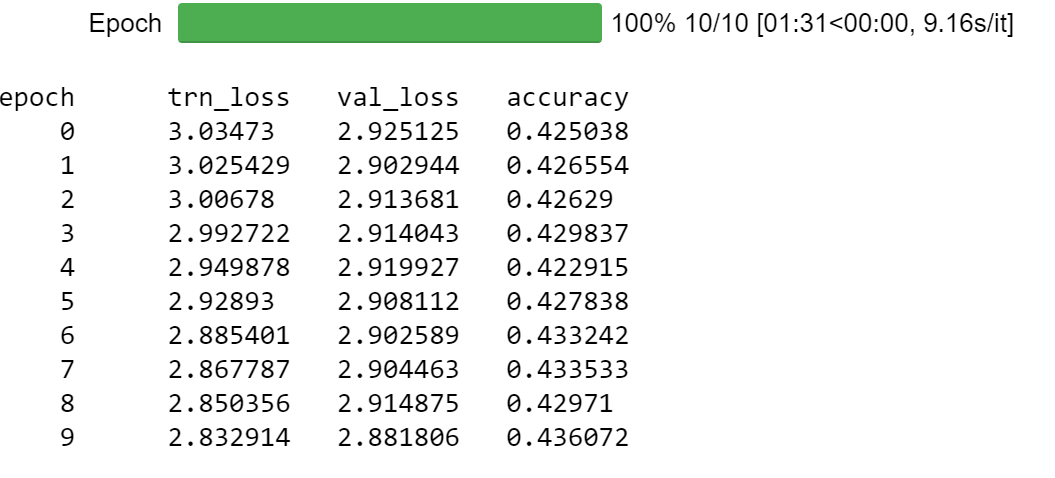
Modeling Approach: Classifier Model
Now that we have fine-tuned the language model, we can now further fine-tune it for our actual task, which was to predict whether the movie quote is memorable or not. This involves simply popping off the last layer and replacing it with a layer with two outputs (memorable, non-memorable). After training for a little while, we get to around 70% validation set accuracy. Not too bad considering the dataset is quite small!
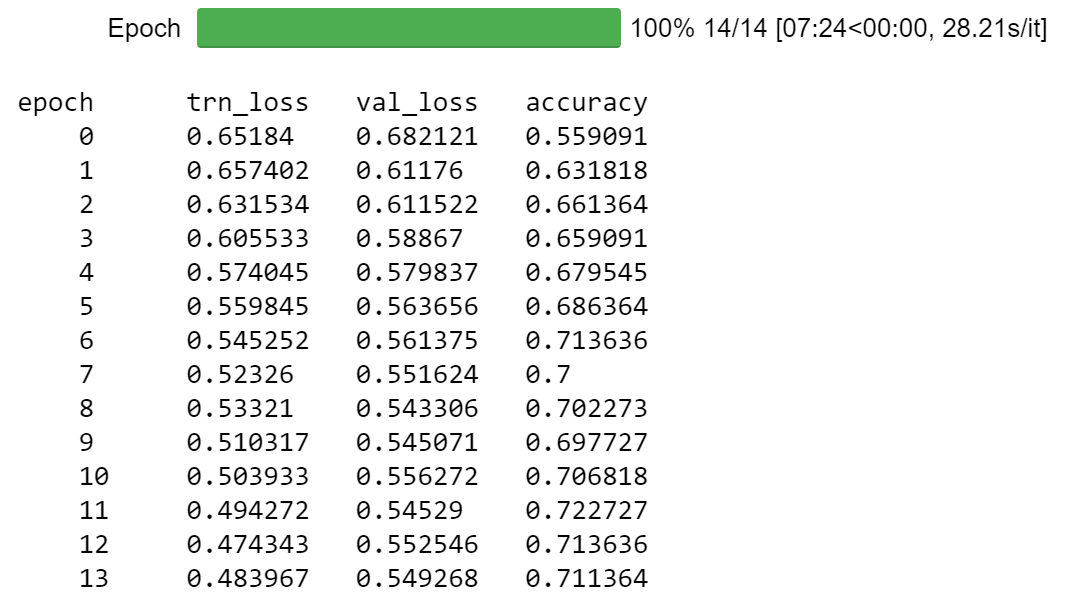
In an attempt to even further improve the accuracy of the model, I re-ran all of the training but with the documents backwards; there are also publicly available pre-trained weights with a backwards language model. This ended up not helping, but is worth examining in your own datasets.
Conclusions
Here, this analysis demonstrates that controlling for length and time presentation of a quote, there is something about the content of certain quotes that make them memorable. The next step may be to try to understand why some quotes are memorable whereas others are not (i.e., model interpretation); actually, this was the original goal of the creators of this dataset. Perhaps this classifier may be used by writers and journalists to check whether a quote will be memorable.
It is really quite amazing that with such a small dataset we can achieve a reasonable level of accuracy. This level of accuracy would be quite difficult to achieve with such a small dataset if we had not used transfer learning. I am really excited to see further use of transfer learning in NLP. There are a lot of other small details on training this model. Check out my GitHub to see the actual code and please do not hesitate to ask if you have any questions!