How SQL Is Making Me a Better Scientist
An explanation of why and how I started using SQL

SQL (Structured Query Language) is a computer language for relational database management and data manipulation. Relational databases and SQL are extremely popular in industry and for a good reason. Relational databases are great when working with large and complex databases. SQL as a language, allows you to efficiently query these databases. SQL is a declarative programming language, which basically means that when writing SQL code you know what it does but you don’t necessarily know how it works. Why SQL is such a powerful language happens all behind the scenes, where it can query databases with extreme efficiency. Since it is a declarative language, if you are familiar with imperative programming languages (e.g., Python), you will find it quite easy to learn. Again, with SQL, groups of individuals dedicated to learning how to efficiently query databases have done the hard work for us and figured out methods to query databases. With SQL, we just tell the computer what we want done.
When I first learned about SQL, I did not think it would be useful for my day-to-day work as a graduate student studying computational cognitive neuroscience. I recognized that since SQL is so popular in industry, I would have to learn it, but I did not intend to use SQL as a student. After thinking a little bit more about how SQL could be used in my workplace, I realized that creating/maintaining relational databases could be extremely useful in my work.
Why I Chose to Start Using SQL
My research investigates a discipline called the cognitive neuroscience of aging, meaning I typically conduct human brain imaging research studies containing samples of human research participants of younger adults (~18–29 years old) and older adults (~65–79 years old). Regarding specifically the older adult participants, it is actually somewhat difficult to find participants that (1) want to participate in research studies that typically span several days and (2) receive an MRI which can last anywhere from 1–2 hours. Therefore, it is more or less the same older adults that participate in my studies and other studies within the lab. Although each study design is different, there are typically similar components of each study. For example, typically all of the studies within the lab contain the same neuropsychological assessments. We are essentially conducting a longitudinal study but don’t even realize it.
Even though we are using the same participants year after year, within the lab there was not a good system to track what participants are completing each of our studies. Essentially every study was independent of each other. It truly was a shame that there was no system in place to track participants over time. That’s when I realized that creating a standardized lab-wide relational database management system has the potential to transform my research. I could create a way to easily track participants over time and maintain their data all in one place. There are several benefits for creating this database management system. First, myself or one of my colleagues could conduct a number of interesting analyses, including tracking participants’ cognitive performance (e.g., memory) over time and see who exhibits cognitive decline, who does not, and what studies have they participated in. Furthermore, creating a relational database management system may save time administering assessments. A colleague and myself may be running two different studies around the same time and administering the same neuropsychological battery. If the same participants complete each study, they should not be given the neuropsychological battery each time in order to avoid practice effects. Lastly, we could collapse data between studies. For example, I predominantly conduct brain imaging studies but some of my colleagues just conduct behavioral studies. A colleague could query the relational database, see that many of his or her participants completed my study, and possibly correlate the behavioral measures with my imaging measures, or vice versa. In sum, the creation of a relational database system has the potential to increase the impact of my work.
Creating the Database
Now that I have made an argument for why I think the creation of the database is beneficial for my work, I’m going to explain how I made this database. I am a beginner to the design of relational databases, so I welcome any feedback. Before creating the database, it is important to create a diagram of the database structure. There are many programs available to do this, but I used DBDiagram, which is completely free. Below is the diagram:
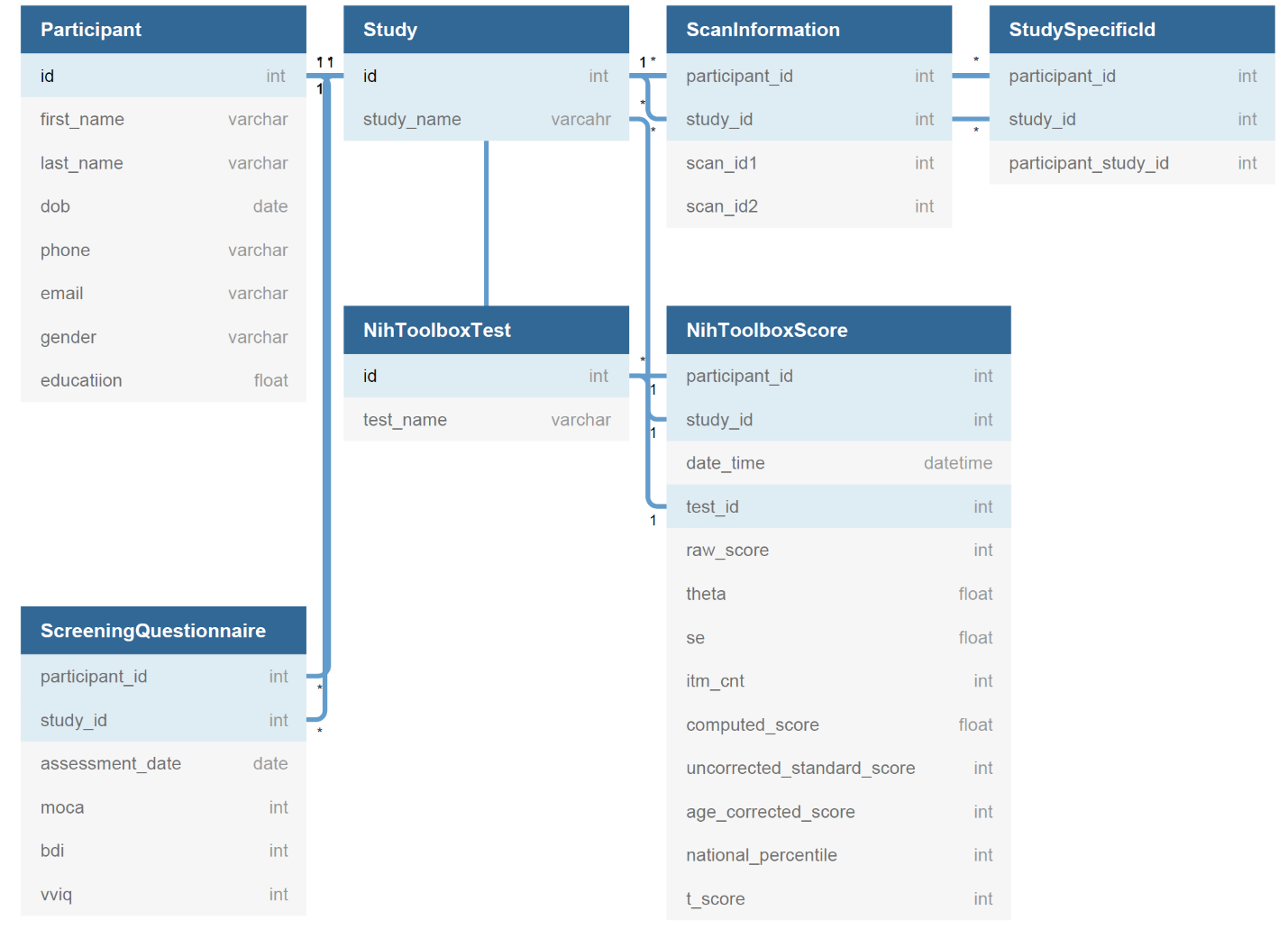
The details of this diagram are not too important, but essentially each participant is assigned a unique participant id and each study is assigned a unique study id. The NIH Toolbox is the neuropsychological battery and there are a few other assessments in the ScreeningQuestionnaire.
To actually create the database I used SQLite and specifically sqlite3 in Python. In order to ensure the data was entered properly, I viewed the database using DB Browser for SQLite. For readers interested in learning SQL, there are a lot of online resources, but I specifically used a Coursera class, Python for Everybody and, most importantly, practiced with my own data!
I am not able to make the data publicly available because it contains participants’ personal information, but you may view the script used to create the database on my GitHub. As of now the database only contains one study, but eventually it will be expanded to include multiple studies and more study data points.
Conclusions
I am confident that my colleagues and myself will benefit from this database. I am excited to see what novel analyses this database will help yield! Lastly, I will end with one last piece of advice, which is if you think you cannot benefit from the use of a relational database, think again. Database management is important at any institution and has the potential to make your life easier and increase the quality of your work.