Developing Python Libraries for Data Scientists

A large proportion of data scientists use Jupyter Notebooks on a daily basis. If you are not familiar with Jupyter Notebooks, you may be asking, why are they so popular among data scientists? And my answer to that question is because they are awesome! Jupyter Notebooks allow for interactive programming. With these notebooks, among many other features, you can easily document your code with markdown, easily view the outputs of cells, and create and view figures. If you have never used Jupyter Notebooks before, I strongly recommend trying them out (here is a good blog post that tells about some of the other cool features of Jupyter Notebooks). These notebooks are perfect for data scientists and all scientists in general. They allow us to easily experiment with creating new models, document our experiments, and easily debug code.
Despite Jupyter Notebooks being a tool commonly used by data scientists to experiment and create models, the actual production code implementing data science projects is rarely written in notebooks. Typically they are written in Python files (i.e., .py files) and this is a somewhat valid choice when working in a production environment. For example, historically, Jupyter Notebooks presented some version control issues. A lot of this has to do with rendering issues. How one computer renders a Jupyter Notebook may be different on another computer, so if two different developers are working on a notebook, this could present some issues. Also, many software engineers are not familiar with Jupyter Notebooks, so it is unlikely that in a team of data scientists and software engineers that the software engineers will want to contribute to and maintain production code written in notebooks (not to say there are not exceptions!). But this is really a shame! Jupyter Notebooks are terrific for documentation and telling a story on how a library was developed. I also find when coding in Juptyer Notebooks that it is easier to debug code and most importantly experiment!
Well fear not! Many of these issues have been resolved with the release of an amazing Python library developed by the fast.ai team called nbdev. Ultimately, the goal of nbdev is to allow for the creation of Python libraries in Jupyter Notebooks. The way this works is that you write the code you would like to be included in the library in Jupyter Notebook and in cells in which you would like to be included in the production code, you include the export tag at the top of the cell (as can be seen in the figure below). When you are ready to export the library, you simply type in the command line, nbdev_build_lib and your code will be exported to Python files. Easy enough!
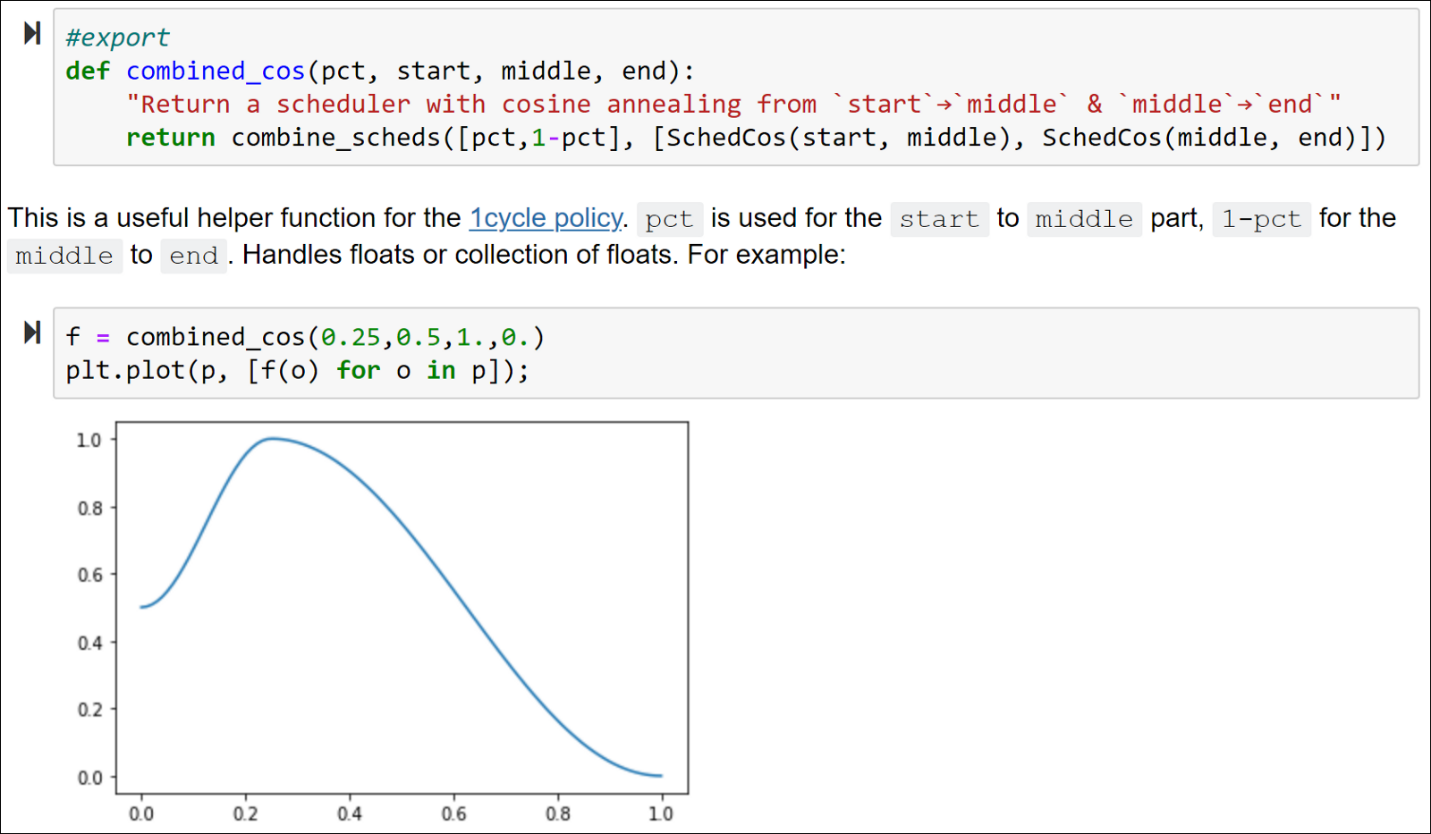 From nbdev website.
From nbdev website.
And, again, the real power in Jupyter Notebooks comes from increased documentation capabilities. nbdev is not just great for easily allowing production code to be developed in notebooks, but also for the integration of documentation. Jupyter Notebooks allow for the use of markdown, which makes it easy to tell a story about/document the code and even demonstrate features about the code. For example, in the figure above, there is documentation describing the combined_cos function and even a plot of example values below. This code will not be exported into the production code and is maintained in the Jupyter Notebook for documentation. This may allow users to easily understand a function. Also, the documentation can be converted to a web page that can be hosted on GitHub Pages, which is very useful (as can be seen in the figure below)! The idea that the code documentation is pulled directly from the source code is powerful and I find it to be an extremely useful feature. No longer do you have to worry about a library’s documentation being up-to-date with the source code, since with nbdev the documentation is pulled directly from the source code.
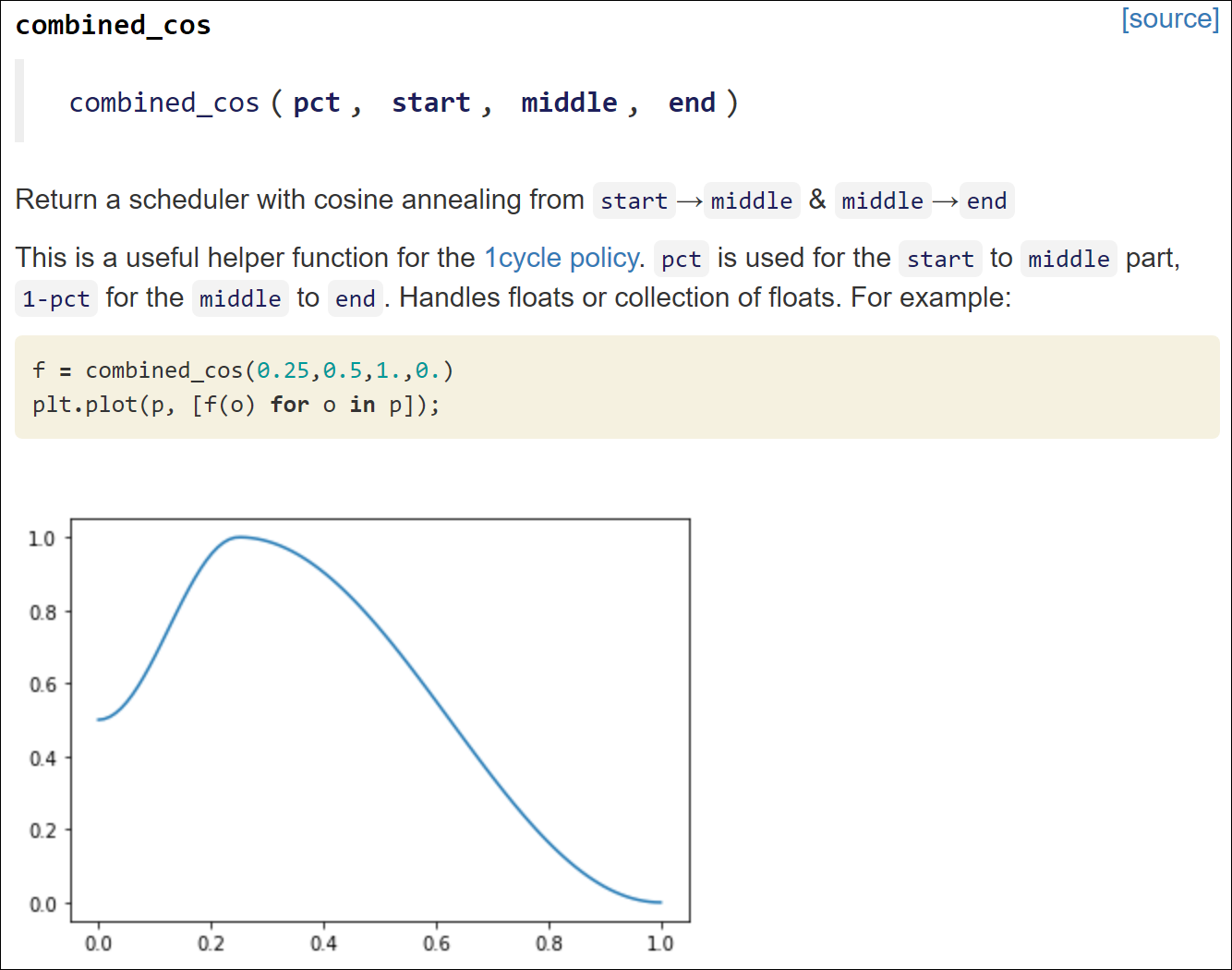 From nbdev website.
From nbdev website.
Conclusions
If you are a data scientist/software engineer, give nbdev a shot! The fast.ai team has an excellent tutorial if you want to get started. I used nbdev to create an anomaly detection library and it was a great experience — I am also finding it easy to maintain this library. There are also many other features of nbdev that I did not describe here (e.g., exporting to pip, resolving merge conflicts) that can be found in the tutorial and nbdev’s documentation. Happy coding and if you are in need of assistance in developing a data science library, visit my website for my contact information!